I always love these breathless stories of great speed, and how VCs love them ...
By joe
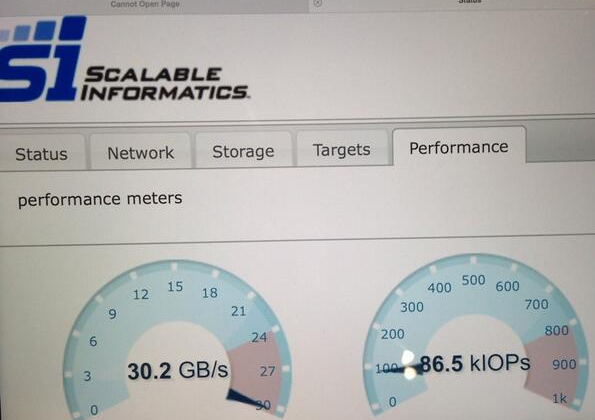
- 2 minutes read - 283 wordsThough, when I look at the “great speed”, it is often on par with or less than Scalable Informatics sustained years before. From 2013 SC13 show, on the show floor, after blasting through a POC at unheard of speed, and setting long standing records in the STAC-M3 benchmarks …
Article in question is in the Register. Some of the speeds and feeds:
* 200 microsecs latency
* 45GBps read bandwidth
* 15GBps write bandwidth
* 7 million IOPS
But then … a fibre connection. And … its an array. Not an appliance. So deduct points. Respectable read bandwidth, chances are they are doing this as reading compressed data, and then counting the uncompressed data as what was read, missing the decompression step. Write perf is low, should be higher. Would need more data on the IOPs to say one way or the other, how did they measure, etc. FWIW, in 2012/2013, Scalable Informatics sustained 30+ GB/s read bandwidth on our siFlash unit for 128 threads of IO, and about 3M IOPs for 128 threads of random 8k reads. In 2015, we hit 24GB/s and 5M IOPs on v1 of Forte. v2 of Forte never saw the light of day because we ran out of money. Specs on that (estimated) are 50GB/s 10M IOPs in a 2U container. And Scalable never got any VC love or cash. A shame, because we set very long standing records in a number of areas, that others are, to some degree, still catching up to, years later. I’m reminded of a little bit of revisionist history put out by IBM at the time, that storage blogger Robin Harris recalled in his great StorageMojo blog. Here is a paraphrase